When I'm building two products in parallel with AI agents, the context I need always exists. PRDs, ADRs, implementation plans, session captures, decisions, audit trails. All of it lives in a repo somewhere. The cost is finding it.
This is the first Build Log post for GovPort. PRD-0017 extracts it from GoldenPath into a standalone product, and this post is about why the extraction had to happen and what GovPort does that I couldn't do with grep, an IDE markdown viewer, or a fresh tab.
The pain
The information existed. PRDs, ADRs, implementation plans, session captures, decisions, audit trails. All of it lived somewhere in a repo. The friction was accessing it at the moment I needed it.
When I'm in flow, opening a markdown file, scrolling for the section, and reconstructing the context I forgot is the last thing I want to do. That trawl forces me to forge a temporary context, which takes me off the work I'm doing. Each context switch carries cost.
Working with AI agents amplifies the problem. Velocity is high. Two prompts and a pull request later, the agent has produced more state than I can hold in my head. The cure is structural: tracking, logging, and relationships between artifacts. Skip them and orientation drifts faster than I can rebuild it.
I'm a visual person. I want to scan and know. Click and see. The information has to surface itself when I need it, ready for a glance.
Decisions stuck in a file somewhere are technically captured but functionally invisible. A real visibility layer connects a decision to its downstream effect, the implementation plan it shaped, and the work that delivered it.
That's the friction GovPort solves.
The trigger moment
I was running Automation Switch work and GoldenPath work in parallel. GoldenPath is Scaletific's flagship platform engineering product. Automation Switch is the publication and product cluster that hosts this Build Log.
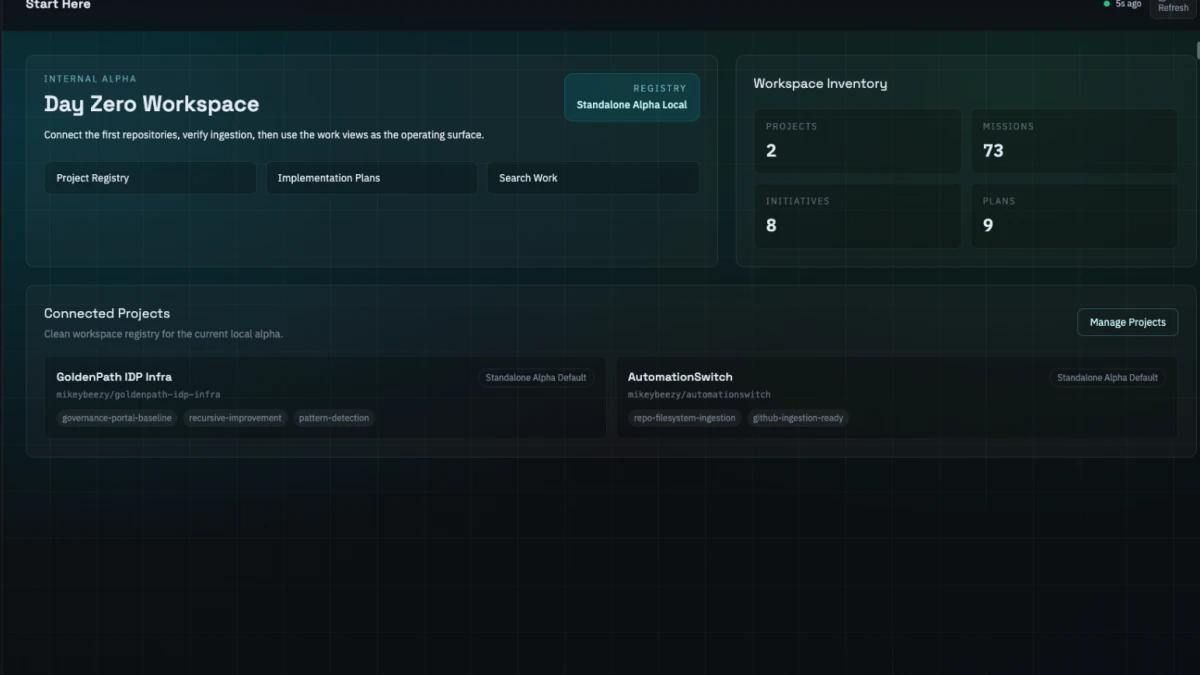
GovPort already existed. It surfaced mission timelines, session captures, and orphan compliance for the GoldenPath repo. The original PRD (PRD-0013) scoped it as single-repo, filesystem-backed. Useful inside one product. Invisible from outside it.
The first time I needed to know what governance work was active across both products in the same week, the answer was: I can't see it from one place. I could open GovPort scoped to GoldenPath. I could open the Automation Switch repository. Neither view showed me the other product's PRDs, session captures, or summaries.
That was the trigger.
The three architectural problems
PRD-0017 names the three problems that forced the extraction.
Cross-project visibility. The embedded GovPort could only see what lived in goldenpath-idp-infra. Automation Switch work needed to live in a separate ecosystem because it serves a different audience and a different commercial position. Pulling AS into GoldenPath's repo just to make it visible was the wrong shape.
Primitive coupling. Recursive self-improvement and pattern detection are platform primitives. They should work across whatever projects an operator runs. The original embedded scope confined them to a single filesystem. Coupling these primitives to GoldenPath blocked them from delivering value across the broader ecosystem.
No durable cross-repo audit ledger. Filesystem-backed views are a snapshot. They cannot capture what happened, why, which artifacts were touched, and which agents participated, in a way that survives across sessions and across repositories. A real audit ledger needs a durable store.
Three problems, one architectural answer: extract GovPort into a standalone product with its own database, its own auth, its own host, and its own MCP endpoint.
PRD-0017 supersedes the single-repo and filesystem-only constraints from PRD-0013 for the standalone product direction. PRD-0013 remains the baseline for the embedded portal capability set. The two PRDs coexist; the standalone direction is owned by PRD-0017.
Automating the audit trail
The reframe behind PRD-0017 is straightforward. GovPort automates the audit trail.
As I work, the artifacts I produce get indexed automatically: PRDs I write, ADRs I land, implementation plans I update, session captures my agents file at the end of each piece of work. The audit trail builds itself in the background as a byproduct of the work. By the time I need to look back at a decision, the lookup is a glance instead of a grep.
That framing matters because it changes what GovPort is for. A governance dashboard captures retrospective state. A visibility layer captures present state and surfaces it on demand. GovPort is the second of those, not the first. It happens to produce a governance trail. The trail is the receipt; the visibility is the product.
For founders and solo builders running multi-product workflows, the framing is direct: a standalone work visibility layer for PRDs, prompts, sessions, agent reports, GitHub evidence, relationships, and audit trails. The Scaletific page positions GovPort for enterprise platform-engineering teams. The framing here is the operator-builder shape — same product, audience-specific positioning.
The primitives
GovPort indexes a small set of artifact types. Each one is a building block for staying organised when work moves fast. For builders new to the pattern:
- PRD (Product Requirements Document). The why, what, and constraints of a piece of work before it ships. Captures problem, goals, requirements, scope, and what is out of scope. PRDs commit to a goal.
- ADR (Architectural Decision Record). The record of an architectural decision and the context that drove it. Captures the choice, the alternatives considered, and the trade-offs. ADRs commit to a choice.
- Implementation plan. The how. Translates a PRD into stages, blockers, evidence, and definition of done. Plans commit to a path.
- Session capture. A record of a specific session's activity, written by each agent at the end of a session or when a piece of work completes. Captures work across multiple agents and pieces them into one trail.
- Session summary. A higher-level rollup of a session. Long-lived, appended in the repo so the synthesis grows over time and survives across sessions.
- Initiative. The outcome cluster. Groups related PRDs, plans, ADRs, session captures, summaries, and evidence under one named goal. Initiatives commit to a destination.
- Extended Capability (EC). A loose idea you might build on later. ECs let you be expressive, hold ideas without committing to them, and graduate the strongest ones into PRDs when they earn it.
Each primitive serves a different layer of the build. PRDs, plans, and session captures handle the work in front of you. ADRs and ECs handle the reasoning behind and the territory ahead. Session summaries hold the long-arc synthesis. Initiatives group the lot.
Working this way looks heavyweight from the outside. In practice, the structure pays for itself the first time someone (including future you) asks why a decision was made. The artifact is the receipt for that question.
What PRD-0017 ships
The Internal Alpha is live at scaletific.com/govport. It registers two initial projects: goldenpath-idp-infra and automationswitch. It indexes PRDs, documents, prompts, prompt templates, session captures, session summaries, GitHub issues, GitHub PRs, commits, decisions, audit events, initiatives, implementation plans, ADRs, and Extended Capabilities. Each artifact has a relationship graph. The PRD-to-work trail walks from a PRD down to the session captures, summaries, and GitHub activity that delivered it.
The wedge is governance-native agent observability. GovPort observes work across multiple projects in a single ledger.
| Artifact | Embedded (PRD-0013) | Standalone GovPort (PRD-0017) |
|---|---|---|
| PRDs | Filesystem listing inside goldenpath-idp-infra | Postgres ledger across registered projects |
| ADRs | Read-only listing | Indexed with relationship graph and supersession chains |
| Implementation plans | Filesystem only | First-class artifacts with stage, blockers, evidence |
| Session captures | Single-repo, written per session | Cross-project, indexed with the rest |
| Session summaries | Per-repo, manual rollup | Long-lived appended file across projects |
| Extended Capabilities | Filesystem listing under docs/extend-capabilities/ | First-class artifacts with graduation tracking into PRDs |
| Audit events | Not durable | Persistent in Postgres |
| Search scope | One repo | All registered projects |
Metadata builds the graph
Artifacts on their own are isolated documents. They become a graph when they carry metadata.
Each markdown artifact in GovPort has a frontmatter block with fields like id, relates_to, supersedes, risk_profile, definition_of_done, and version. Those fields are what GovPort reads to build the relationship graph. Frontmatter turns folders of isolated documents into a graph GovPort can walk: from a PRD down to the ADRs that informed it, to the implementation plan that delivered it, to the session captures and summaries that produced the work.
The metadata is doing the connective work.
Two reasons this matters when you build with AI agents.
First, agent velocity is high. You can ship more in an afternoon than you can mentally track. Metadata is the cheapest way to keep the work coherent without slowing the agent down. Frontmatter takes seconds to write and it pays back every time GovPort surfaces a connection you would otherwise have missed.
Second, metadata is forward-compatible. Today GovPort renders a relationship graph from it. Tomorrow, a knowledge graph or RAG layer can read the same metadata and answer questions over the corpus. The discipline you put in now is what unlocks the queryable surface later. Future Build Logs in this series will go deeper on the knowledge graph and relationship-discovery patterns the metadata enables.
For builders setting this up: pick a metadata schema, document it once, and enforce it in CI. GovPort then becomes the readable surface of that schema. The schema is the discipline. GovPort is what the discipline buys you.
The stack
Same Next.js base as Automation Switch, with Postgres added as the artifact ledger.
- Next.js 15 with React 19. Same framework as AS, same conventions, same operator vocabulary.
- Vercel. Same hosting, same deployment patterns.
- Postgres via Supabase. The artifact ledger, full-text search index, and audit ledger.
- GitHub OAuth. Identity layer that maps the operator's GitHub work directly into GovPort.
- Zod. Schema validation across API boundaries.
- Vitest. Test runner.
- Markdown in Git. The durable home for authored artifacts. The source of truth stays in Git.
- Postgres as the index. The ledger reflects what's in Git rather than replacing it.
- GitHub PRs for generated writes. When GovPort needs to write durable markdown, it does so through a PR rather than overwriting source files.
The stack alignment with Automation Switch is deliberate. Same framework, same hosting, same testing. One operator, one set of mental models. The only addition is Postgres for the artifact ledger and full-text search, which a content site doesn't need but a visibility layer over governance artefacts does.
What changes when one tool watches two products
The cross-product framing is the wedge.
Before the extraction, GovPort was a single-product tool. After PRD-0017, it indexes Automation Switch work and GoldenPath work side by side. When I open GovPort, I see PRDs from both products. I see implementation plans from both. I see session captures from both. The relationship graph spans both.
That changes the daily decisions I make. When a session happens on Automation Switch, GovPort records it. When a session happens on GoldenPath, GovPort records it. Both feed the same orphan-detection logic, the same recursive self-improvement loop, the same pattern detector.
Two products. One operator. One visibility surface. That's the configuration the embedded portal couldn't reach.
Where the alpha is right now
V1 has the multi-project registry working with both initial projects. Artifacts ingest from configured repository paths. Relationships record. Postgres full-text search returns results scoped by project. Project lifecycle (register, detach, reactivate, purge) functions correctly. The MCP endpoint foundation is in place for read-first queries.
A recent V1 enhancement: GovPort now observes operator and agent behaviour to flag repetitive actions worth codifying as skills or prompts. The same artifact registry that surfaces what I worked on also watches how I worked on it. Patterns that show up across sessions become candidates for automation. GovPort moves from visibility into active cognition-load reduction.
Phase 2 is the surface that turns GovPort from a visibility layer into a workflow tool. It ships in stages:
- Governance Explorer. Browseable PRDs, ADRs, capability docs across projects. Today GovPort can search them. Phase 2 lets you walk them.
- ADR graph. Relationships and supersession chains visualised. Today the relationships are stored. Phase 2 renders them.
- Action loop. Open issues from findings, assign owners, track closures. Today GovPort is read-first. Phase 2 makes it actionable.
- Trust UX. Parse errors surfaced, data quality indicators visible, confidence scores shown. Today GovPort silently skips unparseable input. Phase 2 makes the silence visible.
Each Phase 2 milestone gets its own Build Log post when it lands.
Why this is in public
GovPort is proprietary at alpha. The Build Logs document the build journey, not the source code. At beta, the open-source position gets revisited.
The reason I'm publishing the build is that the alternative (build in stealth, ship with a marketing campaign) doesn't fit how the audience for governance tooling makes decisions. Operators evaluating governance products want to see the trade-offs being made in real time. They want the receipts: what shipped, what stuck, what got pulled.
The other reason is asset value. A media-and-product company is more sellable when the build journey is visible. The Build Logs are an editorial artefact independent of the product itself. If the product succeeds, they are a content trail customers can read. If the product changes shape, they are a record of how operators actually build.
What I'm watching for
Three signals I'm tracking on the GovPort alpha:
- First cross-product moment. The first time GovPort surfaces a relationship between an Automation Switch artifact and a GoldenPath artifact in a way I would not have spotted manually. That's when the cross-project thesis stops being theoretical.
- First action loop trigger. The first orphaned mission or SLA violation that GovPort turns into a tracked issue with a closure path. That's the moment the visibility layer becomes a workflow tool.
- First MCP query from another agent. The first time a Claude Code session or another agent uses the read-first MCP endpoint to answer a governance question. That's when the audit ledger earns its keep.
When any of these three lands, the next Build Log post writes itself.
Open question
For operators reading this who run multiple products: where does your governance work currently live? Inside one repository, scattered across many, or in a third tool that doesn't see either? I'm interested in the patterns that aren't extraction stories like this one. Reply on the newsletter or hit me at the contact link.
The full PRD lives at docs/20-contracts/prds/PRD-0017-standalone-governance-portal.md in the governance-portal repository. Subscribe to the Automation Switch newsletter to get the next Build Log post when Phase 2 ships.
How an audit trail builds itself when you work, so you stop trawling docs to find what you already wrote.
